
Automated Hypothesis Generation



.svg)
Automated hypothesis generation: when machine-learning systems produce ideas, not just test them.
Testing ideas at scale. Fast.
While algorithms are mostly used as tools to number-crunch and test-drive ideas, they have yet been used to generate the ideas themselves. Let alone at scale.
Rather than thinking up one idea at a time and testing it, what if a machine could generate millions of ideas automatically? What if this same machine would then proceed to autonomously test and rank the ideas, discovering which are better supported by the data? A machine that can even identify the type of data that could refute one’s theories and challenge existing practices.
This machine lies at the heart of SparkBeyond Discovery: its Hypothesis Engine. The engine automatically generates millions of ideas, many of them novel. Asks questions we would never think to even ask.
This Hypothesis Engine integrates the world’s largest collection of algorithms, and bypasses human cognitive bias to produce millions of ideas, hypotheses and questions in minutes. These hypotheses ensure that any meaningful signals in the data are surfaced. Then, these signals are often immediately actionable, and can be used as predictive features in machine learning models.
Going beyond the bias
Human ideation is inherently limited by cognitive bottlenecks and biases, which restrict us in generating and testing ideas at scale and high throughput. We're also limited by the speed at which we can communicate. We don’t have the capacity to read and comprehend the thousands of scientific articles and patents published every day.
What’s more, the questions we ask are biased by our experience and knowledge, or even our mood.
In data science and research workflows, there are key bottlenecks that limit what a person or team can accomplish while working on a problem within a finite amount of time.
For example, when exploring for useful patterns in data, a data scientist only has time to conceive, engineer, and evaluate a limited number of distinct hypotheses, leaving many areas unexplored.
One of these areas is the gaps within an organization’s own data. This internal data may only reveal part of the story, whereas augmented external data sources can provide valuable contextual information. Without it, hypotheses based only on internal data don’t take into account the influence of external factors, such as weather and local events, or macro-economic factors and market conditions.
Instead, by mapping out the entire spectrum of dynamics that happen on earth,SparkBeyond Discovery connects the dots between every data set that exists and offers a comprehensive viewpoint.
Tap into humanity's collective intelligence
Just like search engines crawl the web for text, our machine started indexing the code, data and knowledge on the web, and amassed one of the world's largest libraries of open-source code functions.
Using both automation and AI, the Hypothesis Engine employs these functions to generate four million hypotheses per minute—a capacity that allows the technology to work through hundreds of good and bad ideas every second.
Related Articles


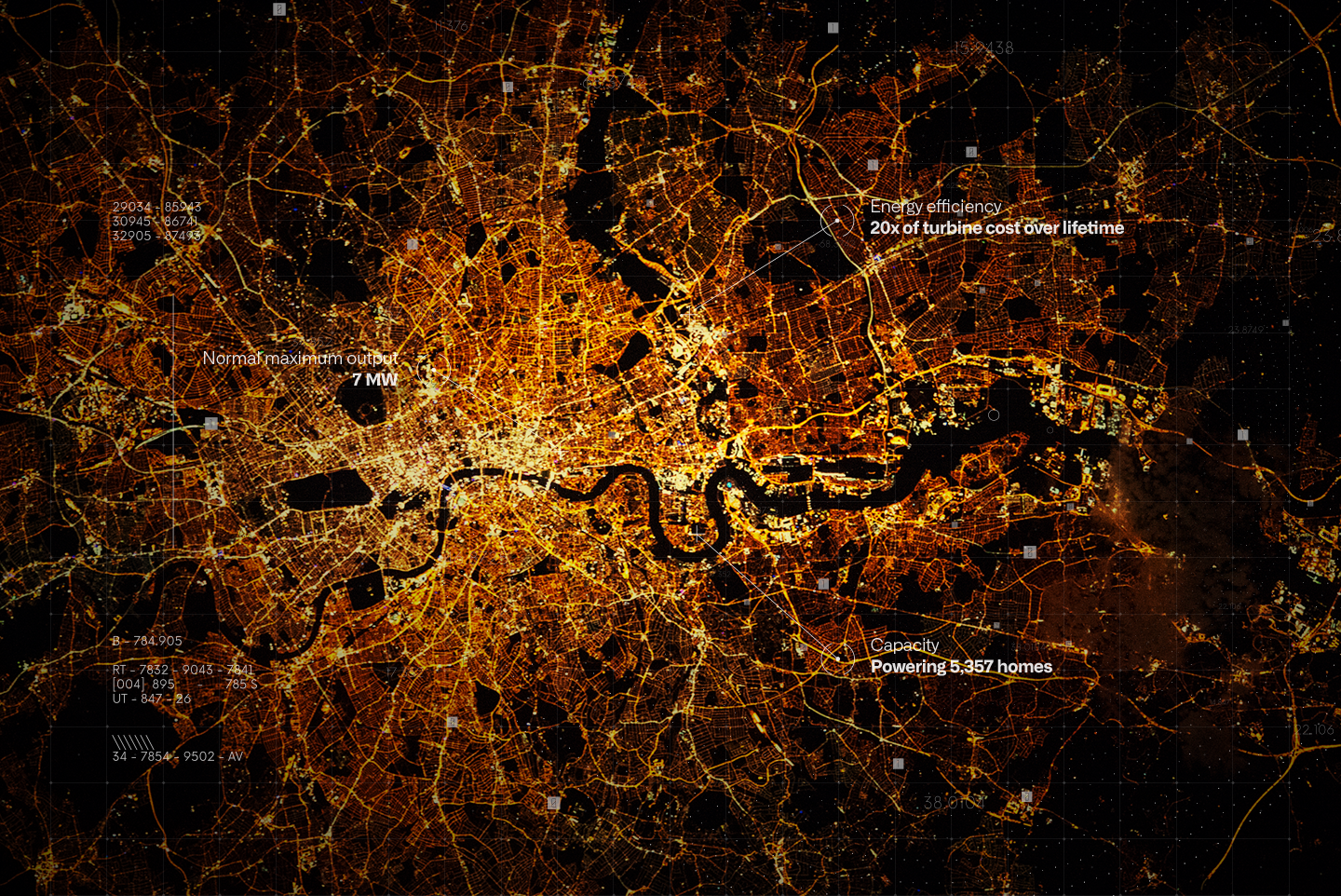

It was easier in this project since we used this outpout
Business Insights
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Predictive Models
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Micro-Segments
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Features For
External Models
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Business Automation
Rules
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis
Root-Cause
Analysis
Apply key dataset transformations through no/low-code workflows to clean, prep, and scope your datasets as needed for analysis







